sksurv.linear_model.CoxnetSurvivalAnalysis#
- class sksurv.linear_model.CoxnetSurvivalAnalysis(*, n_alphas=100, alphas=None, alpha_min_ratio='auto', l1_ratio=0.5, penalty_factor=None, normalize=False, copy_X=True, tol=1e-07, max_iter=100000, verbose=False, fit_baseline_model=False)[source]#
Cox’s proportional hazard’s model with elastic net penalty.
See the User Guide and [1] for further description.
- Parameters:
n_alphas (int, optional, default: 100) – Number of alphas along the regularization path.
alphas (array-like or None, optional) –
List of alphas where to compute the models. If
None, alphas are set automatically.In this case, the
alphassequence is determined by \(\alpha_\max\) andalpha_min_ratio. The latter determines the smallest alpha value \(\alpha_\min\) in the generated alphas sequence such thatalpha_min_ratioequals the ratio \(\frac{\alpha_\min}{\alpha_\max}\). The generatedalphassequence containsn_alphasvalues linear on the log scale from \(\alpha_\max\) down to \(\alpha_\min\). \(\alpha_\max\) is not user-specified but is computed from the input data.alpha_min_ratio (float or { "auto" }, optional, default: "auto") –
Determines the minimum alpha of the regularization path if
alphasisNone. The smallest value for alpha is computed as the fraction of the maximum alpha (i.e. the smallest value for which all coefficients are zero), which is derived from the input data.If set to “auto”, the value will depend on the sample size relative to the number of features:
If
n_samples > n_features, the default value is 0.0001.If
n_samples <= n_features, the default value is 0.01.
l1_ratio (float, optional, default: 0.5) – The ElasticNet mixing parameter, with
0 < l1_ratio <= 1. Forl1_ratio = 0the penalty is an L2 penalty. Forl1_ratio = 1it is an L1 penalty. For0 < l1_ratio < 1, the penalty is a combination of L1 and L2.penalty_factor (array-like or None, optional) –
Separate penalty factors can be applied to each coefficient. This is a number that multiplies alpha to allow differential shrinkage. Can be 0 for some variables, which implies no shrinkage, and that variable is always included in the model. Default is 1 for all variables.
Note: the penalty factors are internally rescaled to sum to n_features, and the alphas sequence will reflect this change.
normalize (bool, optional, default: False) – If True, the features X will be normalized before optimization by subtracting the mean and dividing by the l2-norm. If you wish to standardize, please use
sklearn.preprocessing.StandardScalerbefore callingfiton an estimator withnormalize=False.copy_X (boolean, optional, default: True) – If
True, X will be copied; else, it may be overwritten.tol (float, optional, default: 1e-7) – The tolerance for the optimization: optimization continues until all updates are smaller than
tol.max_iter (int, optional, default: 100000) – The maximum number of iterations taken for the solver to converge.
verbose (bool, optional, default: False) – Whether to print additional information during optimization.
fit_baseline_model (bool, optional, default: False) – Whether to estimate baseline survival function and baseline cumulative hazard function for each alpha. If enabled,
predict_cumulative_hazard_function()andpredict_survival_function()can be used to obtain predicted cumulative hazard function and survival function.
- alphas_#
The actual sequence of alpha values used.
- Type:
ndarray, shape=(n_alphas,)
- alpha_min_ratio_#
The inferred value of alpha_min_ratio.
- Type:
float
- penalty_factor_#
The actual penalty factors used.
- Type:
ndarray, shape=(n_features,)
- coef_#
Matrix of coefficients.
- Type:
ndarray, shape=(n_features, n_alphas)
- offset_#
Bias term to account for non-centered features.
- Type:
ndarray, shape=(n_alphas,)
- deviance_ratio_#
The fraction of (null) deviance explained. The deviance is defined as \(2 \cdot (\text{loglike_sat} - \text{loglike})\), where loglike_sat is the log-likelihood for the saturated model (a model with a free parameter per observation). Null deviance is defined as \(2 \cdot (\text{loglike_sat} - \text{loglike(Null)})\); The NULL model is the model with all zero coefficients. Hence,
deviance_ratio_is \(1 - \frac{\text{deviance}}{\text{null_deviance}}\).- Type:
ndarray, shape=(n_alphas,)
- n_features_in_#
Number of features seen during
fit.- Type:
int
- feature_names_in_#
Names of features seen during
fit. Defined only when X has feature names that are all strings.- Type:
ndarray, shape = (n_features_in_,)
- unique_times_#
Unique time points.
- Type:
ndarray, shape = (n_unique_times,)
References
- __init__(*, n_alphas=100, alphas=None, alpha_min_ratio='auto', l1_ratio=0.5, penalty_factor=None, normalize=False, copy_X=True, tol=1e-07, max_iter=100000, verbose=False, fit_baseline_model=False)[source]#
Methods
__init__(*[, n_alphas, alphas, ...])fit(X, y)Fit estimator.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
predict(X[, alpha])Predict risk scores.
predict_cumulative_hazard_function(X[, ...])Predict cumulative hazard function.
predict_survival_function(X[, alpha, ...])Predict survival function.
score(X, y)Returns the concordance index of the prediction.
set_params(**params)Set the parameters of this estimator.
set_predict_request(*[, alpha])Configure whether metadata should be requested to be passed to the
predictmethod.Attributes
- fit(X, y)[source]#
Fit estimator.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix
y (structured array, shape = (n_samples,)) – A structured array with two fields. The first field is a boolean where
Trueindicates an event andFalseindicates right-censoring. The second field is a float with the time of event or time of censoring.
- Return type:
self
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
routing – A
MetadataRequestencapsulating routing information.- Return type:
MetadataRequest
- get_params(deep=True)#
Get parameters for this estimator.
- Parameters:
deep (bool, default=True) – If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
params – Parameter names mapped to their values.
- Return type:
dict
- predict(X, alpha=None)[source]#
Predict risk scores.
The risk score is the linear predictor of the model, computed as the dot product of the input features X and the estimated coefficients coef_. A higher score indicates a higher risk of experiencing the event.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Test data of which to calculate log-likelihood from
alpha (float, optional) – Constant that multiplies the penalty terms. If the same alpha was used during training, exact coefficients are used, otherwise coefficients are interpolated from the closest alpha values that were used during training. If set to
None, the last alpha in the solution path is used.
- Returns:
risk_score – Predicted risk scores.
- Return type:
array, shape = (n_samples,)
- predict_cumulative_hazard_function(X, alpha=None, return_array=False)[source]#
Predict cumulative hazard function.
Only available if
fit()has been called with fit_baseline_model = True.The cumulative hazard function for an individual with feature vector \(x_\alpha\) is defined as
\[H(t \mid x_\alpha) = \exp(x_\alpha^\top \beta) H_0(t) ,\]where \(H_0(t)\) is the baseline hazard function, estimated by Breslow’s estimator.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix.
alpha (float, optional) – Constant that multiplies the penalty terms. The same alpha as used during training must be specified. If set to
None, the last alpha in the solution path is used.return_array (bool, default: False) –
Whether to return a single array of cumulative hazard values or a list of step functions.
If False, a list of
sksurv.functions.StepFunctionobjects is returned.If True, a 2d-array of shape (n_samples, n_unique_times) is returned, where n_unique_times is the number of unique event times in the training data. Each row represents the cumulative hazard function of an individual evaluated at unique_times_.
- Returns:
cum_hazard – If return_array is False, an array of n_samples
sksurv.functions.StepFunctioninstances is returned.If return_array is True, a numeric array of shape (n_samples, n_unique_times_) is returned.
- Return type:
ndarray
Examples
>>> import matplotlib.pyplot as plt >>> from sksurv.datasets import load_breast_cancer >>> from sksurv.preprocessing import OneHotEncoder >>> from sksurv.linear_model import CoxnetSurvivalAnalysis
Load and prepare the data.
>>> X, y = load_breast_cancer() >>> X = OneHotEncoder().fit_transform(X)
Fit the model.
>>> estimator = CoxnetSurvivalAnalysis( ... l1_ratio=0.99, fit_baseline_model=True ... ).fit(X, y)
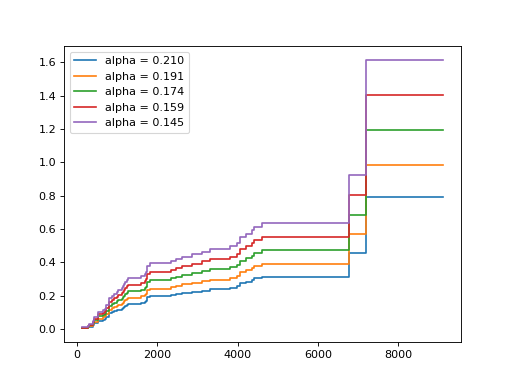
Estimate the cumulative hazard function for one sample and the five highest alpha.
>>> chf_funcs = {} >>> for alpha in estimator.alphas_[:5]: ... chf_funcs[alpha] = estimator.predict_cumulative_hazard_function( ... X.iloc[:1], alpha=alpha) ...
Plot the estimated cumulative hazard functions.
>>> for alpha, chf_alpha in chf_funcs.items(): ... for fn in chf_alpha: ... plt.step(fn.x, fn(fn.x), where="post", ... label=f"alpha = {alpha:.3f}") ... [...] >>> plt.legend() <matplotlib.legend.Legend object at 0x...> >>> plt.show()
- predict_survival_function(X, alpha=None, return_array=False)[source]#
Predict survival function.
Only available if
fit()has been called with fit_baseline_model = True.The survival function for an individual with feature vector \(x_\alpha\) is defined as
\[S(t \mid x_\alpha) = S_0(t)^{\exp(x_\alpha^\top \beta)} ,\]where \(S_0(t)\) is the baseline survival function, estimated by Breslow’s estimator.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix.
alpha (float, optional) – Constant that multiplies the penalty terms. The same alpha as used during training must be specified. If set to
None, the last alpha in the solution path is used.return_array (bool, default: False) –
Whether to return a single array of survival probabilities or a list of step functions.
If False, a list of
sksurv.functions.StepFunctionobjects is returned.If True, a 2d-array of shape (n_samples, n_unique_times) is returned, where n_unique_times is the number of unique event times in the training data. Each row represents the survival function of an individual evaluated at unique_times_.
- Returns:
survival – If return_array is False, an array of n_samples
sksurv.functions.StepFunctioninstances is returned.If return_array is True, a numeric array of shape (n_samples, n_unique_times_) is returned.
- Return type:
ndarray
Examples
>>> import matplotlib.pyplot as plt >>> from sksurv.datasets import load_breast_cancer >>> from sksurv.preprocessing import OneHotEncoder >>> from sksurv.linear_model import CoxnetSurvivalAnalysis
Load and prepare the data.
>>> X, y = load_breast_cancer() >>> X = OneHotEncoder().fit_transform(X)
Fit the model.
>>> estimator = CoxnetSurvivalAnalysis( ... l1_ratio=0.99, fit_baseline_model=True ... ).fit(X, y)
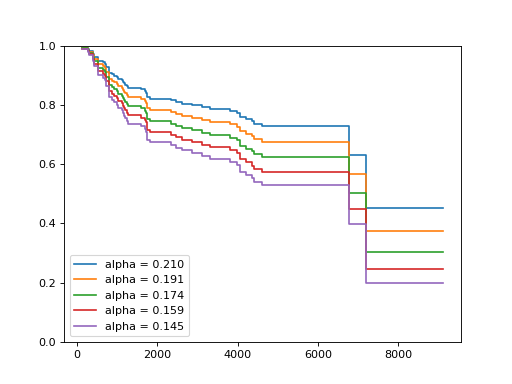
Estimate the survival function for one sample and the five highest alpha.
>>> surv_funcs = {} >>> for alpha in estimator.alphas_[:5]: ... surv_funcs[alpha] = estimator.predict_survival_function( ... X.iloc[:1], alpha=alpha) ...
Plot the estimated survival functions.
>>> for alpha, surv_alpha in surv_funcs.items(): ... for fn in surv_alpha: ... plt.step(fn.x, fn(fn.x), where="post", ... label=f"alpha = {alpha:.3f}") ... [...] >>> plt.ylim(0, 1) (0.0, 1.0) >>> plt.legend() <matplotlib.legend.Legend object at 0x...> >>> plt.show()
- score(X, y)[source]#
Returns the concordance index of the prediction.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Test samples.
y (structured array, shape = (n_samples,)) – A structured array containing the binary event indicator as first field, and time of event or time of censoring as second field.
- Returns:
cindex – Estimated concordance index.
- Return type:
float
See also
sksurv.metrics.concordance_index_censoredComputes the concordance index.
- set_params(**params)#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
**params (dict) – Estimator parameters.
- Returns:
self – Estimator instance.
- Return type:
estimator instance
- set_predict_request(*, alpha: bool | None | str = '$UNCHANGED$') CoxnetSurvivalAnalysis#
Configure whether metadata should be requested to be passed to the
predictmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
alpha (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
alphaparameter inpredict.- Returns:
self – The updated object.
- Return type:
object