sksurv.ensemble.ComponentwiseGradientBoostingSurvivalAnalysis#
- class sksurv.ensemble.ComponentwiseGradientBoostingSurvivalAnalysis(*, loss='coxph', learning_rate=0.1, n_estimators=100, subsample=1.0, warm_start=False, dropout_rate=0, random_state=None, verbose=0)[source]#
Gradient boosting with component-wise least squares as base learner.
See the User Guide and [1] for further description.
- Parameters:
loss ({'coxph', 'squared', 'ipcwls'}, optional, default: 'coxph') – loss function to be optimized. ‘coxph’ refers to partial likelihood loss of Cox’s proportional hazards model. The loss ‘squared’ minimizes a squared regression loss that ignores predictions beyond the time of censoring, and ‘ipcwls’ refers to inverse-probability of censoring weighted least squares error.
learning_rate (float, optional, default: 0.1) – learning rate shrinks the contribution of each base learner by learning_rate. There is a trade-off between learning_rate and n_estimators. Values must be in the range [0.0, inf).
n_estimators (int, optional, default: 100) – The number of boosting stages to perform. Gradient boosting is fairly robust to over-fitting so a large number usually results in better performance. Values must be in the range [1, inf).
subsample (float, optional, default: 1.0) – The fraction of samples to be used for fitting the individual base learners. If smaller than 1.0 this results in Stochastic Gradient Boosting. subsample interacts with the parameter n_estimators. Choosing subsample < 1.0 leads to a reduction of variance and an increase in bias. Values must be in the range (0.0, 1.0].
warm_start (bool, optional, default: False) – When set to
True, reuse the solution of the previous call to fit and add more estimators to the ensemble, otherwise, just erase the previous solution.dropout_rate (float, optional, default: 0.0) – If larger than zero, the residuals at each iteration are only computed from a random subset of base learners. The value corresponds to the percentage of base learners that are dropped. In each iteration, at least one base learner is dropped. This is an alternative regularization to shrinkage, i.e., setting learning_rate < 1.0. Values must be in the range [0.0, 1.0).
random_state (int, RandomState instance or None, optional, default: None) – Controls the randomness of the subsampling of the data if
subsample < 1.0, and the random selection of base learners to drop ifdropout_rate > 0. Pass an int for reproducible output across multiple function calls.verbose (int, optional, default: 0) – Enable verbose output. If 1 then it prints progress and performance once in a while. Values must be in the range [0, inf).
- coef_#
The aggregated coefficients. The first element coef_[0] corresponds to the intercept. If loss is coxph, the intercept will always be zero.
- Type:
ndarray, shape = (n_features + 1,), dtype = float
- estimators_#
The collection of fitted sub-estimators.
- Type:
list of base learners
- train_score_#
The i-th score
train_score_[i]is the loss of the model at iterationion the in-bag sample. Ifsubsample == 1this is the loss on the training data.- Type:
ndarray, shape = (n_estimators,)
- oob_improvement_#
The improvement in loss on the out-of-bag samples relative to the previous iteration.
oob_improvement_[0]is the improvement in loss of the first stage over theinitestimator. Only available ifsubsample < 1.0.- Type:
ndarray, shape = (n_estimators,)
- oob_scores_#
The full history of the loss values on the out-of-bag samples. Only available if
subsample < 1.0.- Type:
ndarray, shape = (n_estimators,)
- oob_score_#
The last value of the loss on the out-of-bag samples. It is the same as
oob_scores_[-1]. Only available ifsubsample < 1.0.- Type:
float
- n_features_in_#
Number of features seen during
fit.- Type:
int
- feature_names_in_#
Names of features seen during
fit. Defined only when X has feature names that are all strings.- Type:
ndarray, shape = (n_features_in_,)
- unique_times_#
Unique time points.
- Type:
ndarray, shape = (n_unique_times,)
References
- __init__(*, loss='coxph', learning_rate=0.1, n_estimators=100, subsample=1.0, warm_start=False, dropout_rate=0, random_state=None, verbose=0)[source]#
Methods
__init__(*[, loss, learning_rate, ...])fit(X, y[, sample_weight])Fit estimator.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
predict(X)Predict risk scores.
predict_cumulative_hazard_function(X[, ...])Predict cumulative hazard function.
predict_survival_function(X[, return_array])Predict survival function.
score(X, y)Returns the concordance index of the prediction.
set_fit_request(*[, sample_weight])Configure whether metadata should be requested to be passed to the
fitmethod.set_params(**params)Set the parameters of this estimator.
Attributes
feature_importances_- fit(X, y, sample_weight=None)[source]#
Fit estimator.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix
y (structured array, shape = (n_samples,)) – A structured array with two fields. The first field is a boolean where
Trueindicates an event andFalseindicates right-censoring. The second field is a float with the time of event or time of censoring.sample_weight (array-like, shape = (n_samples,), optional) – Weights given to each sample. If omitted, all samples have weight 1.
- Return type:
self
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
routing – A
MetadataRequestencapsulating routing information.- Return type:
MetadataRequest
- get_params(deep=True)#
Get parameters for this estimator.
- Parameters:
deep (bool, default=True) – If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
params – Parameter names mapped to their values.
- Return type:
dict
- predict(X)[source]#
Predict risk scores.
If loss=’coxph’, predictions can be interpreted as log hazard ratio corresponding to the linear predictor of a Cox proportional hazards model. If loss=’squared’ or loss=’ipcwls’, predictions are the time to event.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix.
- Returns:
risk_score – Predicted risk scores.
- Return type:
array, shape = (n_samples,)
- predict_cumulative_hazard_function(X, return_array=False)[source]#
Predict cumulative hazard function.
Only available if
fit()has been called with loss = “coxph”.The cumulative hazard function for an individual with feature vector \(x\) is defined as
\[H(t \mid x) = \exp(f(x)) H_0(t) ,\]where \(f(\cdot)\) is the additive ensemble of base learners, and \(H_0(t)\) is the baseline hazard function, estimated by Breslow’s estimator.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix.
return_array (bool, default: False) –
Whether to return a single array of cumulative hazard values or a list of step functions.
If False, a list of
sksurv.functions.StepFunctionobjects is returned.If True, a 2d-array of shape (n_samples, n_unique_times) is returned, where n_unique_times is the number of unique event times in the training data. Each row represents the cumulative hazard function of an individual evaluated at unique_times_.
- Returns:
cum_hazard – If return_array is False, an array of n_samples
sksurv.functions.StepFunctioninstances is returned.If return_array is True, a numeric array of shape (n_samples, n_unique_times_) is returned.
- Return type:
ndarray
Examples
>>> import matplotlib.pyplot as plt >>> from sksurv.datasets import load_veterans_lung_cancer >>> from sksurv.preprocessing import OneHotEncoder >>> from sksurv.ensemble import ComponentwiseGradientBoostingSurvivalAnalysis
Load the data and encode categorical features.
>>> X, y = load_veterans_lung_cancer() >>> Xt = OneHotEncoder().fit_transform(X)
Fit the model.
>>> estimator = ComponentwiseGradientBoostingSurvivalAnalysis().fit(Xt, y)
Estimate the cumulative hazard function for the first 10 samples.
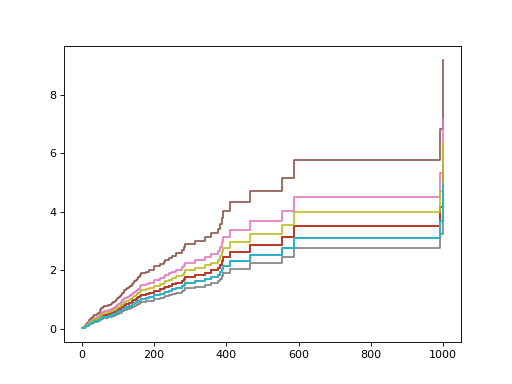
>>> chf_funcs = estimator.predict_cumulative_hazard_function(Xt.iloc[:10])
Plot the estimated cumulative hazard functions.
>>> for fn in chf_funcs: ... plt.step(fn.x, fn(fn.x), where="post") ... [...] >>> plt.show()
- predict_survival_function(X, return_array=False)[source]#
Predict survival function.
Only available if
fit()has been called with loss = “coxph”.The survival function for an individual with feature vector \(x\) is defined as
\[S(t \mid x) = S_0(t)^{\exp(f(x)} ,\]where \(f(\cdot)\) is the additive ensemble of base learners, and \(S_0(t)\) is the baseline survival function, estimated by Breslow’s estimator.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Data matrix.
return_array (bool, default: False) –
Whether to return a single array of survival probabilities or a list of step functions.
If False, a list of
sksurv.functions.StepFunctionobjects is returned.If True, a 2d-array of shape (n_samples, n_unique_times) is returned, where n_unique_times is the number of unique event times in the training data. Each row represents the survival function of an individual evaluated at unique_times_.
- Returns:
survival – If return_array is False, an array of n_samples
sksurv.functions.StepFunctioninstances is returned.If return_array is True, a numeric array of shape (n_samples, n_unique_times_) is returned.
- Return type:
ndarray
Examples
>>> import matplotlib.pyplot as plt >>> from sksurv.datasets import load_veterans_lung_cancer >>> from sksurv.preprocessing import OneHotEncoder >>> from sksurv.ensemble import ComponentwiseGradientBoostingSurvivalAnalysis
Load the data and encode categorical features.
>>> X, y = load_veterans_lung_cancer() >>> Xt = OneHotEncoder().fit_transform(X)
Fit the model.
>>> estimator = ComponentwiseGradientBoostingSurvivalAnalysis().fit(Xt, y)
Estimate the survival function for the first 10 samples.
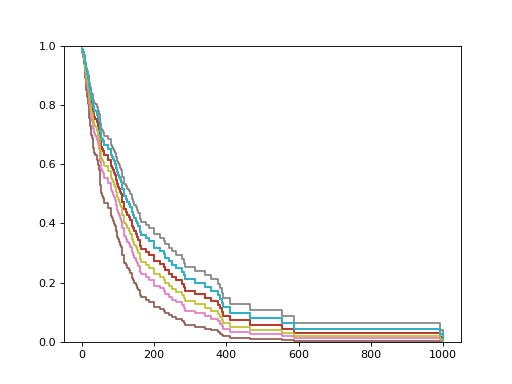
>>> surv_funcs = estimator.predict_survival_function(Xt.iloc[:10])
Plot the estimated survival functions.
>>> for fn in surv_funcs: ... plt.step(fn.x, fn(fn.x), where="post") ... [...] >>> plt.ylim(0, 1) (0.0, 1.0) >>> plt.show()
- score(X, y)[source]#
Returns the concordance index of the prediction.
- Parameters:
X (array-like, shape = (n_samples, n_features)) – Test samples.
y (structured array, shape = (n_samples,)) – A structured array containing the binary event indicator as first field, and time of event or time of censoring as second field.
- Returns:
cindex – Estimated concordance index.
- Return type:
float
See also
sksurv.metrics.concordance_index_censoredComputes the concordance index.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') ComponentwiseGradientBoostingSurvivalAnalysis#
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
sample_weight (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
sample_weightparameter infit.- Returns:
self – The updated object.
- Return type:
object
- set_params(**params)#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
**params (dict) – Estimator parameters.
- Returns:
self – Estimator instance.
- Return type:
estimator instance