Interactive online version:
Evaluating Survival Models#
scikit-survival provides several performance metrics for evaluating survival models:
Concordance Index (C-index): Measures the rank correlation between predicted risk scores and observed event times.
concordance_index_censored(): Implements Harrell’s estimator, which can be optimistic with high censoring.
concordance_index_ipcw(): An inverse probability of censoring weighted (IPCW) alternative that provides a less biased estimate, especially with high censoring.
Cumulative/Dynamic Area Under the ROC Curve (AUC):
cumulative_dynamic_auc(): Extends the AUC to survival data, quantifying how well a model distinguishes subjects who experience an event by a given time from those who do not. It can handle time-dependent risk scores.
Brier Score: An extension of the mean squared error to right-censored data, assessing both discrimination and calibration based on a model’s estimated survival functions.
brier_score(): Computes the Brier score at specific time points.
integrated_brier_score(): Provides an overall measure by integrating the Brier score over a range of time points.

The most frequently used evaluation metric of survival models is the concordance index (c index, c statistic). It is a measure of rank correlation between predicted risk scores \(\hat{f}\) and observed time points \(y\) that is closely related to Kendall’s τ. It is defined as the ratio of correctly ordered (concordant) pairs to comparable pairs. Two samples \(i\) and \(j\) are comparable if the sample with lower observed time \(y\) experienced an event, i.e., if \(y_j > y_i\) and \(\delta_i = 1\), where \(\delta_i\) is a binary event indicator. A comparable pair \((i, j)\) is concordant if the estimated risk \(\hat{f}\) by a survival model is higher for subjects with lower survival time, i.e., \(\hat{f}_i > \hat{f}_j \land y_j > y_i\), otherwise the pair is discordant. Harrell’s estimator of the c index is implemented in concordance_index_censored.
While Harrell’s concordance index is easy to interpret and compute, it has some shortcomings:
it has been shown that it is too optimistic with increasing amount of censoring [1],
it is not a useful measure of performance if a specific time range is of primary interest (e.g. predicting death within 2 years).
Since version 0.8, scikit-survival supports an alternative estimator of the concordance index from right-censored survival data, implemented in concordance_index_ipcw, that addresses the first issue.
The second point can be addressed by extending the well known receiver operating characteristic curve (ROC curve) to possibly censored survival times. Given a time point \(t\), we can estimate how well a predictive model can distinguishing subjects who will experience an event by time \(t\) (sensitivity) from those who will not (specificity). The function cumulative_dynamic_auc implements an estimator of the cumulative/dynamic area under the ROC for a given list of time points.
The first part of this notebook will illustrate the first issue with simulated survival data, while the second part will focus on the time-dependent area under the ROC applied to data from a real study. Finally, part three will discuss the time-dependent Brier score, which is an extension of the mean squared error to right-censored data.
[1]:
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
import pandas as pd
from sklearn import set_config
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sksurv.datasets import load_flchain, load_gbsg2
from sksurv.functions import StepFunction
from sksurv.linear_model import CoxnetSurvivalAnalysis, CoxPHSurvivalAnalysis
from sksurv.metrics import (
concordance_index_censored,
concordance_index_ipcw,
cumulative_dynamic_auc,
integrated_brier_score,
)
from sksurv.nonparametric import kaplan_meier_estimator
from sksurv.preprocessing import OneHotEncoder, encode_categorical
from sksurv.util import Surv
set_config(display="text") # displays text representation of estimators
plt.rcParams["figure.figsize"] = [7.2, 4.8]
Bias of Harrell’s Concordance Index#
Harrell’s concordance index is known to be biased upwards if the amount of censoring in the test data is high [1]. Uno et al proposed an alternative estimator of the concordance index that behaves better in such situations. In this section, we are going to apply concordance_index_censored and concordance_index_ipcw to synthetic survival data and compare their results.
Simulation Study#
We are generating a synthetic biomarker by sampling from a standard normal distribution. For a given hazard ratio, we compute the associated (actual) survival time by drawing from an exponential distribution. The censoring times were generated from a uniform independent distribution \(\textrm{Uniform}(0,\gamma)\), where we choose \(\gamma\) to produce different amounts of censoring.
Since Uno’s estimator is based on inverse probability of censoring weighting, we need to estimate the probability of being censored at a given time point. This probability needs to be non-zero for all observed time points. Therefore, we restrict the test data to all samples with observed time lower than the maximum event time \(\tau\). Usually, one would use the tau argument of concordance_index_ipcw for this, but we apply the selection before to pass identical inputs to
concordance_index_censored and concordance_index_ipcw. The estimates of the concordance index are therefore restricted to the interval \([0, \tau]\).
[2]:
import scipy.optimize as opt
def generate_marker(n_samples, hazard_ratio, baseline_hazard, rnd):
# create synthetic risk score
X = rnd.standard_normal(size=(n_samples, 1))
# create linear model
hazard_ratio = np.array([hazard_ratio])
logits = np.dot(X, np.log(hazard_ratio))
# draw actual survival times from exponential distribution,
# refer to Bender et al. (2005), https://doi.org/10.1002/sim.2059
u = rnd.uniform(size=n_samples)
time_event = -np.log(u) / (baseline_hazard * np.exp(logits))
# compute the actual concordance in the absence of censoring
X = np.squeeze(X)
actual = concordance_index_censored(np.ones(n_samples, dtype=bool), time_event, X)
return X, time_event, actual[0]
def generate_survival_data(n_samples, hazard_ratio, baseline_hazard, percentage_cens, rnd):
X, time_event, actual_c = generate_marker(n_samples, hazard_ratio, baseline_hazard, rnd)
def get_observed_time(x):
[rnd_cens] = rnd.spawn(1)
# draw censoring times
time_censor = rnd_cens.uniform(high=x, size=n_samples)
event = time_event < time_censor
time = np.where(event, time_event, time_censor)
return event, time
def censoring_amount(x):
event, _ = get_observed_time(x)
cens = 1.0 - event.sum() / event.shape[0]
return (cens - percentage_cens) ** 2
# search for upper limit to obtain the desired censoring amount
res = opt.minimize_scalar(censoring_amount, method="bounded", bounds=(0, time_event.max()))
# compute observed time
event, time = get_observed_time(res.x)
# upper time limit such that the probability
# of being censored is non-zero for `t > tau`
tau = time[event].max()
y = Surv.from_arrays(event=event, time=time)
mask = time < tau
X_test = X[mask]
y_test = y[mask]
return X_test, y_test, y, actual_c
def simulation(n_samples, hazard_ratio, n_repeats=100):
measures = (
"censoring",
"Harrel's C",
"Uno's C",
)
data_mean = {}
data_std = {}
for measure in measures:
data_mean[measure] = []
data_std[measure] = []
rnd = np.random.default_rng(seed=20211229)
# iterate over different amount of censoring
for cens in (0.1, 0.25, 0.4, 0.5, 0.6, 0.7):
data = {
"censoring": [],
"Harrel's C": [],
"Uno's C": [],
}
# repeaditly perform simulation
for _ in range(n_repeats):
# generate data
X_test, y_test, y_train, actual_c = generate_survival_data(
n_samples, hazard_ratio, baseline_hazard=0.1, percentage_cens=cens, rnd=rnd
)
# estimate c-index
c_harrell = concordance_index_censored(y_test["event"], y_test["time"], X_test)
c_uno = concordance_index_ipcw(y_train, y_test, X_test)
# save results
data["censoring"].append(100.0 - y_test["event"].sum() * 100.0 / y_test.shape[0])
data["Harrel's C"].append(actual_c - c_harrell[0])
data["Uno's C"].append(actual_c - c_uno[0])
# aggregate results
for key, values in data.items():
data_mean[key].append(np.mean(data[key]))
data_std[key].append(np.std(data[key], ddof=1))
data_mean = pd.DataFrame.from_dict(data_mean)
data_std = pd.DataFrame.from_dict(data_std)
return data_mean, data_std
def plot_results(data_mean, data_std, **kwargs):
index = pd.Index(data_mean["censoring"].round(3), name="mean percentage censoring")
for df in (data_mean, data_std):
df.drop("censoring", axis=1, inplace=True)
df.index = index
ax = data_mean.plot.bar(yerr=data_std, **kwargs)
ax.set_ylabel("Actual C - Estimated C")
ax.yaxis.grid(True)
ax.axhline(0.0, color="gray")
Let us assume a moderate hazard ratio of 2 and generate a small synthetic dataset of 100 samples from which we estimate the concordance index. We repeat this experiment 200 times and plot mean and standard deviation of the difference between the actual (in the absence of censoring) and estimated concordance index.
Since the hazard ratio remains constant and only the amount of censoring changes, we would want an estimator for which the difference between the actual and estimated c to remain approximately constant across simulations.
[3]:
hazard_ratio = 2.0
ylim = [-0.035, 0.035]
mean_1, std_1 = simulation(100, hazard_ratio)
plot_results(mean_1, std_1, ylim=ylim)
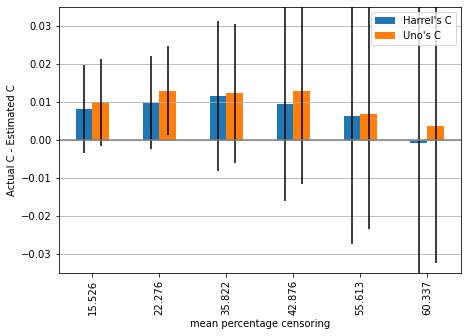
We can observe that estimates are on average below the actual value, except for the highest amount of censoring, where Harrell’s c begins overestimating the performance (on average).
With such a small dataset, the variance of differences is quite big, so let us increase the amount of data to 1000 and repeat the simulation (this may take some time).
[4]:
mean_2, std_2 = simulation(1000, hazard_ratio)
plot_results(mean_2, std_2, ylim=ylim)
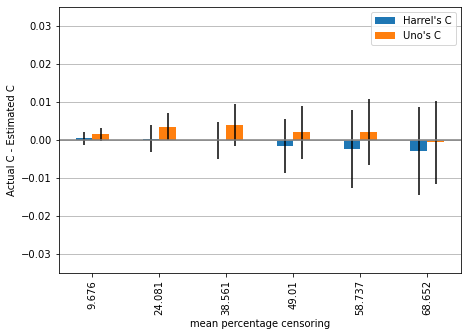
Now we can observe that Harrell’s c begins to overestimate performance starting with approximately 49% censoring while Uno’s c is still underestimating the performance, but is on average very close to the actual performance for large amounts of censoring.
For the final experiment, we double the size of the dataset to 2000 samples and repeat the analysis (this may take several minutes to compute).
[5]:
mean_3, std_3 = simulation(2000, hazard_ratio)
plot_results(mean_3, std_3, ylim=ylim)
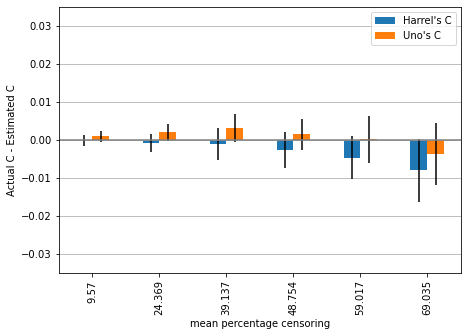
The trend we observed in the previous simulation is now even more pronounced. Harrell’s c is becoming more and more overconfident in the performance of the synthetic marker with increasing amount of censoring, while Uno’s c remains stable.
In summary, while the difference between concordance_index_ipcw and concordance_index_censored is negligible for small amounts of censoring, when analyzing survival data with moderate to high amounts of censoring, you might want to consider estimating the performance using concordance_index_ipcw instead of concordance_index_censored.
Time-dependent Area under the ROC#
The area under the receiver operating characteristics curve (ROC curve) is a popular performance measure for binary classification task. In the medical domain, it is often used to determine how well estimated risk scores can separate diseased patients (cases) from healthy patients (controls). Given a predicted risk score \(\hat{f}\), the ROC curve compares the false positive rate (1 - specificity) against the true positive rate (sensitivity) for each possible value of \(\hat{f}\).
When extending the ROC curve to continuous outcomes, in particular survival time, a patient’s disease status is typically not fixed and changes over time: at enrollment a subject is usually healthy, but may be diseased at some later time point. Consequently, sensitivity and specificity become time-dependent measures. Here, we consider cumulative cases and dynamic controls at a given time point \(t\), which gives rise to the time-dependent cumulative/dynamic ROC at time \(t\). Cumulative cases are all individuals that experienced an event prior to or at time \(t\) (\(t_i \leq t\)), whereas dynamic controls are those with \(t_i>t\). By computing the area under the cumulative/dynamic ROC at time \(t\), we can determine how well a model can distinguish subjects who fail by a given time (\(t_i \leq t\)) from subjects who fail after this time (\(t_i>t\)). Hence, it is most relevant if one wants to predict the occurrence of an event in a period up to time \(t\) rather than at a specific time point \(t\).
The cumulative_dynamic_auc function implements an estimator of the cumulative/dynamic area under the ROC at a given list of time points. To illustrate its use, we are going to use data from a study that investigated to which extent the serum immunoglobulin free light chain (FLC) assay can be used predict overall survival. The dataset has 7874 subjects and 9 features; the endpoint is death, which occurred for 2169 subjects (27.5%).
First, we are loading the data and split it into train and test set to evaluate how well markers generalize.
[6]:
x, y = load_flchain()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
Serum creatinine measurements are missing for some patients, therefore we are just going to impute these values with the mean using scikit-learn’s SimpleImputer.
[7]:
num_columns = ["age", "creatinine", "kappa", "lambda"]
imputer = SimpleImputer().fit(x_train.loc[:, num_columns])
x_test_imputed = imputer.transform(x_test.loc[:, num_columns])
Similar to Uno’s estimator of the concordance index described above, we need to be a little bit careful when selecting the test data and time points we want to evaluate the ROC at, due to the estimator’s dependence on inverse probability of censoring weighting. First, we are going to check whether the observed time of the test data lies within the observed time range of the training data.
[8]:
y_events = y_train[y_train["death"]]
train_min, train_max = y_events["futime"].min(), y_events["futime"].max()
y_events = y_test[y_test["death"]]
test_min, test_max = y_events["futime"].min(), y_events["futime"].max()
assert (
train_min <= test_min < test_max < train_max
), "time range or test data is not within time range of training data."
When choosing the time points to evaluate the ROC at, it is important to remember to choose the last time point such that the probability of being censored after the last time point is non-zero. In the simulation study above, we set the upper bound to the maximum event time, here we use a more conservative approach by setting the upper bound to the 80% percentile of observed time points, because the censoring rate is quite large at 72.5%. Note that this approach would be appropriate for choosing
tau of concordance_index_ipcw too.
[9]:
times = np.percentile(y["futime"], np.linspace(5, 81, 15))
print(times)
[ 470.3 1259. 1998. 2464.82428571 2979.
3401. 3787.99857143 4051. 4249. 4410.17285714
4543. 4631. 4695. 4781. 4844. ]
We begin by considering individual real-valued features as risk scores without actually fitting a survival model. Hence, we obtain an estimate of how well age, creatinine, kappa FLC, and lambda FLC are able to distinguish cases from controls at each time point.
[10]:
def plot_cumulative_dynamic_auc(risk_score, label, color=None):
auc, mean_auc = cumulative_dynamic_auc(y_train, y_test, risk_score, times)
plt.plot(times, auc, marker="o", color=color, label=label)
plt.xlabel("days from enrollment")
plt.ylabel("time-dependent AUC")
plt.axhline(mean_auc, color=color, linestyle="--")
plt.legend()
for i, col in enumerate(num_columns):
plot_cumulative_dynamic_auc(x_test_imputed[:, i], col, color=f"C{i}")
ret = concordance_index_ipcw(y_train, y_test, x_test_imputed[:, i], tau=times[-1])
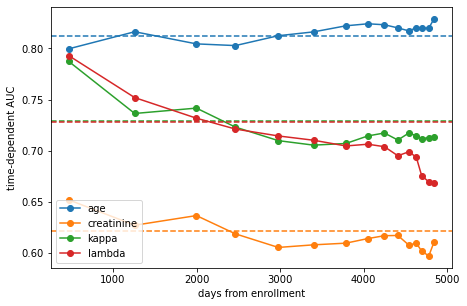
The plot shows the estimated area under the time-dependent ROC at each time point and the average across all time points as dashed line.
We can see that age is overall the most discriminative feature, followed by \(\kappa\) and \(\lambda\) FLC. That fact that age is the strongest predictor of overall survival in the general population is hardly surprising (we have to die at some point after all). More differences become evident when considering time: the discriminative power of FLC decreases at later time points, while that of age increases. The observation for age again follows common sense. In contrast, FLC seems to be a good predictor of death in the near future, but not so much if it occurs decades later.
Evaluating a Model’s Predictions#
Most of the time, we do not want to evaluate the discriminatory power of individual features, but how a predictive model performs, based on many features. To demonstrate this, we will fit a survival model to predict the risk of death from the Veterans’ Administration Lung Cancer Trial.
First, we split the data into 80% for training and 20% for testing and use the stratify option to ensure that we do not end up with test data only containing censored death times.
[11]:
from sksurv.datasets import load_veterans_lung_cancer
va_x, va_y = load_veterans_lung_cancer()
va_x_train, va_x_test, va_y_train, va_y_test = train_test_split(
va_x, va_y, test_size=0.2, stratify=va_y["Status"], random_state=0
)
Next, we fit a Cox proportional hazards model to the training data.
[12]:
cph = make_pipeline(OneHotEncoder(), CoxPHSurvivalAnalysis())
cph.fit(va_x_train, va_y_train)
[12]:
Pipeline(steps=[('onehotencoder', OneHotEncoder()),
('coxphsurvivalanalysis', CoxPHSurvivalAnalysis())])
Using the test data, we want to assess how well the model can distinguish survivors from deceased in weekly intervals, up to 6 months after enrollment.
[13]:
va_times = np.arange(8, 184, 7)
cph_risk_scores = cph.predict(va_x_test)
cph_auc, cph_mean_auc = cumulative_dynamic_auc(va_y_train, va_y_test, cph_risk_scores, va_times)
plt.plot(va_times, cph_auc, marker="o")
plt.axhline(cph_mean_auc, linestyle="--")
plt.xlabel("days from enrollment")
plt.ylabel("time-dependent AUC")
plt.grid(True)
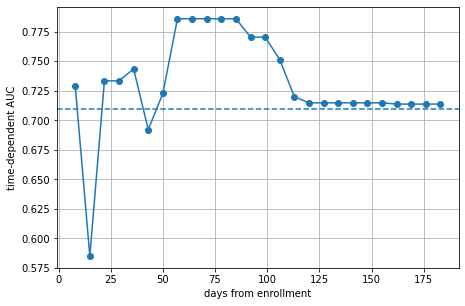
The plot shows that the model is doing moderately well on average with an AUC of ~0.72 (dashed line). However, there is a clear difference in performance between the first and second half of the time range. The performance on the test data increases up to 56 days from enrollment, remains high until 98 days and quickly drops thereafter. Thus, we can conclude that the model is most effective in predicting death in the medium-term.
Using Time-dependent Risk Scores#
The downside of Cox proportional hazards model is that it can only predict a risk score that is independent of time (due to the built-in proportional hazards assumption). Therefore, a single predicted risk score needs to work well for every time point. In contrast, a Random Survival Forest does not have this restriction. So let’s fit such a model to the training data.
[14]:
from sksurv.ensemble import RandomSurvivalForest
rsf = make_pipeline(OneHotEncoder(), RandomSurvivalForest(n_estimators=100, min_samples_leaf=7, random_state=0))
rsf.fit(va_x_train, va_y_train)
[14]:
Pipeline(steps=[('onehotencoder', OneHotEncoder()),
('randomsurvivalforest',
RandomSurvivalForest(min_samples_leaf=7, random_state=0))])
For prediction, we do not call predict, which returns a time-independent risk score, but call predict_cumulative_hazard_function, which returns a risk function over time for each patient. We obtain the time-dependent risk scores by evaluating each cumulative hazard function at the time points we are interested in.
[15]:
rsf_chf_funcs = rsf.predict_cumulative_hazard_function(va_x_test, return_array=False)
rsf_risk_scores = np.vstack([chf(va_times) for chf in rsf_chf_funcs])
rsf_auc, rsf_mean_auc = cumulative_dynamic_auc(va_y_train, va_y_test, rsf_risk_scores, va_times)
Now, we can compare the result with the predictive performance of the Cox proportional hazards model from above.
[16]:
plt.plot(va_times, cph_auc, "o-", label=f"CoxPH (mean AUC = {cph_mean_auc:.3f})")
plt.plot(va_times, rsf_auc, "o-", label=f"RSF (mean AUC = {rsf_mean_auc:.3f})")
plt.xlabel("days from enrollment")
plt.ylabel("time-dependent AUC")
plt.legend(loc="lower center")
plt.grid(True)
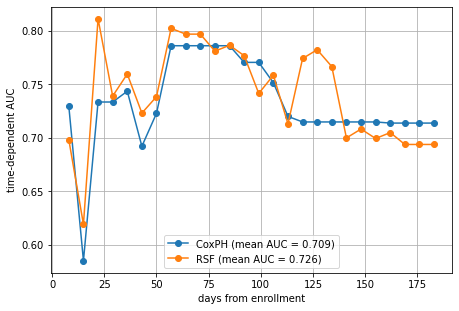
Indeed, the Random Survival Forest performs slightly better on average, mostly due to the better performance in the intervals 25–50 days, and 112–147 days. Above 147 days, it actually is doing worse. This shows that the mean AUC is convenient to assess overall performance, but it can hide interesting characteristics that only become visible when looking at the AUC at individual time points.
Time-dependent Brier Score#
The time-dependent Brier score is an extension of the mean squared error to right censored data. Given a time point \(t\), it is defined as:
where \(\hat{\pi}(t | \mathbf{x})\) is a model’s predicted probability of remaining event-free up to time point \(t\) for feature vector \(\mathbf{x}\), and \(1/\hat{G}(t)\) is an inverse probability of censoring weight.
Note that the time-dependent Brier score is only applicable for models that are able to estimate a survival function. For instance, it cannot be used with Survival Support Vector Machines.
The Brier score is often used to assess calibration. If a model predicts a 10% risk of experiencing an event at time \(t\), the observed frequency in the data should match this percentage for a well calibrated model. In addition, the Brier score is also a measure of discrimination: whether a model is able to predict risk scores that allow us to correctly determine the order of events. The concordance index is probably the most common measure of discrimination. However, the concordance index disregards the actual values of predicted risk scores – it is a ranking metric – and is unable to tell us anything about calibration.
Let’s consider an example based on data from the German Breast Cancer Study Group 2.
[17]:
gbsg_X, gbsg_y = load_gbsg2()
gbsg_X = encode_categorical(gbsg_X)
gbsg_X_train, gbsg_X_test, gbsg_y_train, gbsg_y_test = train_test_split(
gbsg_X, gbsg_y, stratify=gbsg_y["cens"], random_state=1
)
We want to train a model on the training data and assess its discrimination and calibration on the test data. Here, we consider a Random Survival Forest and Cox’s proportional hazards model with elastic-net penalty.
[18]:
rsf_gbsg = RandomSurvivalForest(max_depth=2, random_state=1)
rsf_gbsg.fit(gbsg_X_train, gbsg_y_train)
cph_gbsg = CoxnetSurvivalAnalysis(l1_ratio=0.99, fit_baseline_model=True)
cph_gbsg.fit(gbsg_X_train, gbsg_y_train)
[18]:
CoxnetSurvivalAnalysis(fit_baseline_model=True, l1_ratio=0.99)
First, let’s start with discrimination as measured by the concordance index.
[19]:
score_cindex = pd.Series(
[
rsf_gbsg.score(gbsg_X_test, gbsg_y_test),
cph_gbsg.score(gbsg_X_test, gbsg_y_test),
0.5,
],
index=["RSF", "CPH", "Random"],
name="c-index",
)
score_cindex.round(3)
[19]:
RSF 0.692
CPH 0.688
Random 0.500
Name: c-index, dtype: float64
The result indicates that both models perform almost equally well with Cox’s proportional hazards model achieving a concordance index of 0.688 and Random Survival Forest of 0.692, both of which are significantly better than a random model with 0.5 concordance index. Unfortunately, it doesn’t help us to decide which model we should choose. So let’s consider the time-dependent Brier score as an alternative, which asses discrimination and calibration.
We first need to determine for which time points \(t\) we want to compute the Brier score for. We are going to use a data-driven approach here by selecting all time points between the 10% and 90% percentile of observed time points.
[20]:
lower, upper = np.percentile(gbsg_y["time"], [10, 90])
gbsg_times = np.arange(lower, upper + 1)
This returns 1690 time points, for which we need to estimate the probability of survival for, which is given by the survival function. Thus, we iterate over the predicted survival functions on the test data and evaluate each at the time points from above.
[21]:
rsf_surv_prob = np.vstack([fn(gbsg_times) for fn in rsf_gbsg.predict_survival_function(gbsg_X_test)])
cph_surv_prob = np.vstack([fn(gbsg_times) for fn in cph_gbsg.predict_survival_function(gbsg_X_test)])
In addition, we want to have a baseline to tell us how much better our models are from random. A random model would simply predict 0.5 every time.
[22]:
random_surv_prob = 0.5 * np.ones((gbsg_y_test.shape[0], gbsg_times.shape[0]))
Another useful reference is the Kaplan-Meier estimator that does not consider any features: it estimates a survival function only from gbsg_y_test. We replicate this estimate for all samples in the test data.
[23]:
km_func = StepFunction(*kaplan_meier_estimator(gbsg_y_test["cens"], gbsg_y_test["time"]))
km_surv_prob = np.tile(km_func(gbsg_times), (gbsg_y_test.shape[0], 1))
Instead of comparing calibration across all 1690 time points, we’ll be using the integrated Brier score (IBS) over all time points, which will give us a single number to compare the models by.
[24]:
score_brier = pd.Series(
[
integrated_brier_score(gbsg_y, gbsg_y_test, prob, gbsg_times)
for prob in (rsf_surv_prob, cph_surv_prob, random_surv_prob, km_surv_prob)
],
index=["RSF", "CPH", "Random", "Kaplan-Meier"],
name="IBS",
)
pd.concat((score_cindex, score_brier), axis=1).round(3)
[24]:
| c-index | IBS | |
|---|---|---|
| RSF | 0.692 | 0.192 |
| CPH | 0.688 | 0.189 |
| Random | 0.500 | 0.247 |
| Kaplan-Meier | NaN | 0.217 |
Despite Random Survival Forest and Cox’s proportional hazards model performing equally well in terms of discrimination (c-index), there seems to be a notable difference in terms of calibration (IBS), with Cox’s proportional hazards model outperforming Random Survival Forest.
Using Metrics in Hyper-parameter Search#
Usually, estimators have hyper-parameters that one wants to optimize. For example, the maximum tree depth for tree-based learners. For this purpose, we can use scikit-learn’s GridSearchCV to search for the hyper-parameter configuration that on average works best. By default, estimators’ performance will be evaluated in terms of Harrell’s concordance index, as implemented in concordance_index_censored. For other metrics, one can wrap an estimator with one of the following classes:
[25]:
from sklearn.model_selection import GridSearchCV, KFold
from sksurv.metrics import (
as_concordance_index_ipcw_scorer,
as_cumulative_dynamic_auc_scorer,
as_integrated_brier_score_scorer,
)
To illustrate this, we are going to use the Random Survival Forest and the German Breast Cancer Study Group 2 from above.
First, we define that we want to evaluate the performance of each hyper-parameter configuration by 3-fold cross-validation.
[26]:
cv = KFold(n_splits=3, shuffle=True, random_state=1)
Next, we define the set of hyper-parameters to evaluate. Here, we search for the best value for max_depth between 1 and 10 (excluding). Note that we have to prefix max_depth with estimator__, because we are going to wrap the actual RandomSurvivalForest instance with one of the classes above.
[27]:
cv_param_grid = {
"estimator__max_depth": np.arange(1, 10, dtype=int),
}
Now, we can put all the pieces together and start searching for the best hyper-parameters that maximize concordance_index_ipcw.
[28]:
gcv_cindex = GridSearchCV(
as_concordance_index_ipcw_scorer(rsf_gbsg, tau=gbsg_times[-1]),
param_grid=cv_param_grid,
cv=cv,
).fit(gbsg_X, gbsg_y)
The same process applies when optimizing hyper-parameters to maximize cumulative_dynamic_auc.
[29]:
gcv_iauc = GridSearchCV(
as_cumulative_dynamic_auc_scorer(rsf_gbsg, times=gbsg_times),
param_grid=cv_param_grid,
cv=cv,
).fit(gbsg_X, gbsg_y)
While as_concordance_index_ipcw_scorer and as_cumulative_dynamic_auc_scorer can be used with any estimator, as_integrated_brier_score_scorer is only available for estimators that provide the predict_survival_function method, which includes RandomSurvivalForest. If
available, hyper-parameters that maximize the negative integrated time-dependent Brier score will be selected, because a lower Brier score indicates better performance.
[30]:
gcv_ibs = GridSearchCV(
as_integrated_brier_score_scorer(rsf_gbsg, times=gbsg_times),
param_grid=cv_param_grid,
cv=cv,
).fit(gbsg_X, gbsg_y)
Finally, we can visualize the results of the grid search and compare the best performing hyper-parameter configurations (marked with a red dot).
[31]:
def plot_grid_search_results(gcv, ax, name):
ax.errorbar(
x=gcv.cv_results_["param_estimator__max_depth"].filled(),
y=gcv.cv_results_["mean_test_score"],
yerr=gcv.cv_results_["std_test_score"],
)
ax.plot(
gcv.best_params_["estimator__max_depth"],
gcv.best_score_,
"ro",
)
ax.set_ylabel(name)
ax.yaxis.grid(True)
_, axs = plt.subplots(3, 1, figsize=(6, 6), sharex=True)
axs[-1].set_xlabel("max_depth")
plot_grid_search_results(gcv_cindex, axs[0], "c-index")
plot_grid_search_results(gcv_iauc, axs[1], "iAUC")
plot_grid_search_results(gcv_ibs, axs[2], "$-$IBS")
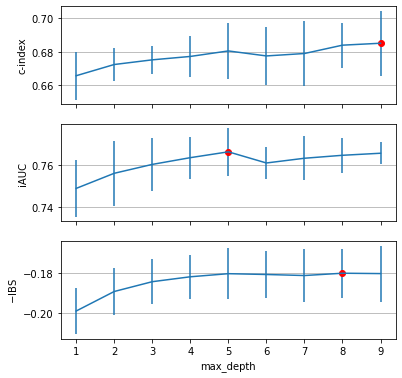
When optimizing for the concordance index, a high maximum depth works best, whereas the other metrics are best when choosing a maximum depth of 5 and 8, respectively.
Conclusion#
I hope this notebook helped you to understand some of the pitfalls when estimating the performance of markers and models from right-censored survival data. We illustrated that Harrell’s estimator of the concordance index is biased when the amount of censoring is high, and that Uno’s estimator is more appropriate in this situation. Finally, we demonstrated that the time-dependent area under the ROC is a very useful tool when we want to predict the occurrence of an event in a period up to time \(t\) rather than at a specific time point \(t\). Finally, the integrated time-dependent Brier score is an extension of the mean squared error that can measure discrimination and calibration.