Introduction to Survival Analysis with scikit-survival#
scikit-survival is a Python module for survival analysis built on top of scikit-learn. It allows doing survival analysis while utilizing the power of scikit-learn, e.g., for pre-processing or doing cross-validation.
Table of Contents#
What is Survival Analysis?#
The objective in survival analysis — also referred to as reliability analysis in engineering — is to establish a connection between covariates and the time of an event. The name survival analysis originates from clinical research, where predicting the time to death, i.e., survival, is often the main objective. Survival analysis is a type of regression problem (one wants to predict a continuous value), but with a twist. It differs from traditional regression by the fact that parts of the training data can only be partially observed – they are censored.
As an example, consider a clinical study, which investigates coronary heart disease and has been carried out over a 1 year period as in the figure below.

Patient A was lost to follow-up after three months with no recorded cardiovascular event, patient B experienced an event four and a half months after enrollment, patient D withdrew from the study two months after enrollment, and patient E did not experience any event before the study ended. Consequently, the exact time of a cardiovascular event could only be recorded for patients B and C; their records are uncensored. For the remaining patients it is unknown whether they did or did not experience an event after termination of the study. The only valid information that is available for patients A, D, and E is that they were event-free up to their last follow-up. Therefore, their records are censored.
Formally, each patient record consists of a set of covariates \(x \in \mathbb{R}^d\) , and the time \(t>0\) when an event occurred or the time \(c>0\) of censoring. Since censoring and experiencing and event are mutually exclusive, it is common to define an event indicator \(\delta \in \{0;1\}\) and the observable survival time \(y>0\). The observable time \(y\) of a right censored sample is defined as
Consequently, survival analysis demands for models that take this unique characteristic of such a dataset into account, some of which are showcased below.
The Veterans’ Administration Lung Cancer Trial#
The Veterans’ Administration Lung Cancer Trial is a randomized trial of two treatment regimens for lung cancer. The data set (Kalbfleisch J. and Prentice R, (1980) The Statistical Analysis of Failure Time Data. New York: Wiley) consists of 137 patients and 8 variables, which are described below:
Treatment: denotes the type of lung cancer treatment;standardandtestdrug.Celltype: denotes the type of cell involved;squamous,small cell,adeno,large.Karnofsky_score: is the Karnofsky score.Diag: is the time since diagnosis in months.Age: is the age in years.Prior_Therapy: denotes any prior therapy;noneoryes.Status: denotes the status of the patient as dead or alive;deadoralive.Survival_in_days: is the survival time in days since the treatment.
Our primary interest is studying whether there are subgroups that differ in survival and whether we can predict survival times.
Survival Data#
As described in the section What is Survival Analysis? above, survival times are subject to right-censoring, therefore, we need to consider an individual’s status in addition to survival time. To be fully compatible with scikit-learn, Status and Survival_in_days need to be stored as a structured array with the first field indicating whether the actual survival time was observed or if was censored, and the second field denoting the
observed survival time, which corresponds to the time of death (if Status == 'dead', \(\delta = 1\)) or the last time that person was contacted (if Status == 'alive', \(\delta = 0\)).
[1]:
from sksurv.datasets import load_veterans_lung_cancer
data_x, data_y = load_veterans_lung_cancer()
data_y
[1]:
array([( True, 72.), ( True, 411.), ( True, 228.), ( True, 126.),
( True, 118.), ( True, 10.), ( True, 82.), ( True, 110.),
( True, 314.), (False, 100.), ( True, 42.), ( True, 8.),
( True, 144.), (False, 25.), ( True, 11.), ( True, 30.),
( True, 384.), ( True, 4.), ( True, 54.), ( True, 13.),
(False, 123.), (False, 97.), ( True, 153.), ( True, 59.),
( True, 117.), ( True, 16.), ( True, 151.), ( True, 22.),
( True, 56.), ( True, 21.), ( True, 18.), ( True, 139.),
( True, 20.), ( True, 31.), ( True, 52.), ( True, 287.),
( True, 18.), ( True, 51.), ( True, 122.), ( True, 27.),
( True, 54.), ( True, 7.), ( True, 63.), ( True, 392.),
( True, 10.), ( True, 8.), ( True, 92.), ( True, 35.),
( True, 117.), ( True, 132.), ( True, 12.), ( True, 162.),
( True, 3.), ( True, 95.), ( True, 177.), ( True, 162.),
( True, 216.), ( True, 553.), ( True, 278.), ( True, 12.),
( True, 260.), ( True, 200.), ( True, 156.), (False, 182.),
( True, 143.), ( True, 105.), ( True, 103.), ( True, 250.),
( True, 100.), ( True, 999.), ( True, 112.), (False, 87.),
(False, 231.), ( True, 242.), ( True, 991.), ( True, 111.),
( True, 1.), ( True, 587.), ( True, 389.), ( True, 33.),
( True, 25.), ( True, 357.), ( True, 467.), ( True, 201.),
( True, 1.), ( True, 30.), ( True, 44.), ( True, 283.),
( True, 15.), ( True, 25.), (False, 103.), ( True, 21.),
( True, 13.), ( True, 87.), ( True, 2.), ( True, 20.),
( True, 7.), ( True, 24.), ( True, 99.), ( True, 8.),
( True, 99.), ( True, 61.), ( True, 25.), ( True, 95.),
( True, 80.), ( True, 51.), ( True, 29.), ( True, 24.),
( True, 18.), (False, 83.), ( True, 31.), ( True, 51.),
( True, 90.), ( True, 52.), ( True, 73.), ( True, 8.),
( True, 36.), ( True, 48.), ( True, 7.), ( True, 140.),
( True, 186.), ( True, 84.), ( True, 19.), ( True, 45.),
( True, 80.), ( True, 52.), ( True, 164.), ( True, 19.),
( True, 53.), ( True, 15.), ( True, 43.), ( True, 340.),
( True, 133.), ( True, 111.), ( True, 231.), ( True, 378.),
( True, 49.)],
dtype=[('Status', '?'), ('Survival_in_days', '<f8')])
We can easily see that only a few survival times are right-censored (Status is False), i.e., most veteran’s died during the study period (Status is True).
The Survival Function#
A key quantity in survival analysis is the so-called survival function, which relates time to the probability of surviving beyond a given time point.
Let \(T\) denote a continuous non-negative random variable corresponding to a patient’s survival time. The survival function \(S(t)\) returns the probability of survival beyond time \(t\) and is defined as
\[S(t) = P (T > t).\]
If we observed the exact survival time of all subjects, i.e., everyone died before the study ended, the survival function at time \(t\) can simply be estimated by the ratio of patients surviving beyond time \(t\) and the total number of patients:
In the presence of censoring, this estimator cannot be used, because the numerator is not always defined. For instance, consider the following set of patients:
[2]:
import pandas as pd
pd.DataFrame.from_records(data_y[[11, 5, 32, 13, 23]], index=range(1, 6))
[2]:
| Status | Survival_in_days | |
|---|---|---|
| 1 | True | 8.0 |
| 2 | True | 10.0 |
| 3 | True | 20.0 |
| 4 | False | 25.0 |
| 5 | True | 59.0 |
Using the formula from above, we can compute \(\hat{S}(t=11) = \frac{3}{5}\), but not \(\hat{S}(t=30)\), because we don’t know whether the 4th patient is still alive at \(t = 30\), all we know is that when we last checked at \(t = 25\), the patient was still alive.
An estimator, similar to the one above, that is valid if survival times are right-censored is the Kaplan-Meier estimator.
[3]:
%matplotlib inline
import matplotlib.pyplot as plt
from sksurv.nonparametric import kaplan_meier_estimator
time, survival_prob, conf_int = kaplan_meier_estimator(
data_y["Status"], data_y["Survival_in_days"], conf_type="log-log"
)
plt.step(time, survival_prob, where="post")
plt.fill_between(time, conf_int[0], conf_int[1], alpha=0.25, step="post")
plt.ylim(0, 1)
plt.ylabel(r"est. probability of survival $\hat{S}(t)$")
plt.xlabel("time $t$")
[3]:
Text(0.5, 0, 'time $t$')
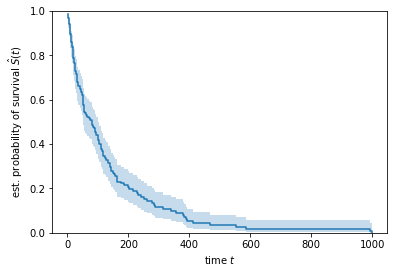
The estimated curve is a step function, with steps occurring at time points where one or more patients died. From the plot we can see that most patients died in the first 200 days, as indicated by the steep slope of the estimated survival function in the first 200 days.
Considering other variables by stratification#
Survival functions by treatment#
Patients enrolled in the Veterans’ Administration Lung Cancer Trial were randomized to one of two treatments: standard and a new test drug. Next, let’s have a look at how many patients underwent the standard treatment and how many received the new drug.
[4]:
data_x["Treatment"].value_counts()
[4]:
Treatment
standard 69
test 68
Name: count, dtype: int64
Roughly half the patients received the alternative treatment.
The obvious questions to ask is: > Is there any difference in survival between the two treatment groups?
As a first attempt, we can estimate the survival function in both treatment groups separately.
[5]:
for treatment_type in ("standard", "test"):
mask_treat = data_x["Treatment"] == treatment_type
time_treatment, survival_prob_treatment, conf_int = kaplan_meier_estimator(
data_y["Status"][mask_treat],
data_y["Survival_in_days"][mask_treat],
conf_type="log-log",
)
plt.step(time_treatment, survival_prob_treatment, where="post", label=f"Treatment = {treatment_type}")
plt.fill_between(time_treatment, conf_int[0], conf_int[1], alpha=0.25, step="post")
plt.ylim(0, 1)
plt.ylabel(r"est. probability of survival $\hat{S}(t)$")
plt.xlabel("time $t$")
plt.legend(loc="best")
[5]:
<matplotlib.legend.Legend at 0x120beee40>
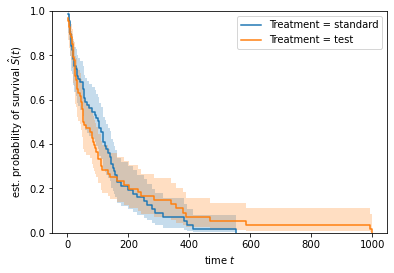
Unfortunately, the results are inconclusive, because the difference between the two estimated survival functions is too small to confidently argue that the drug affects survival or not.
Sidenote: Visually comparing estimated survival curves in order to assess whether there is a difference in survival between groups is usually not recommended, because it is highly subjective. Statistical tests such as the log-rank test are usually more appropriate.
Survival functions by cell type#
Next, let’s have a look at the cell type, which has been recorded as well, and repeat the analysis from above.
[6]:
for value in data_x["Celltype"].unique():
mask = data_x["Celltype"] == value
time_cell, survival_prob_cell, conf_int = kaplan_meier_estimator(
data_y["Status"][mask], data_y["Survival_in_days"][mask], conf_type="log-log"
)
plt.step(time_cell, survival_prob_cell, where="post", label=f"{value} (n = {mask.sum()})")
plt.fill_between(time_cell, conf_int[0], conf_int[1], alpha=0.25, step="post")
plt.ylim(0, 1)
plt.ylabel(r"est. probability of survival $\hat{S}(t)$")
plt.xlabel("time $t$")
plt.legend(loc="best")
[6]:
<matplotlib.legend.Legend at 0x120eb8190>
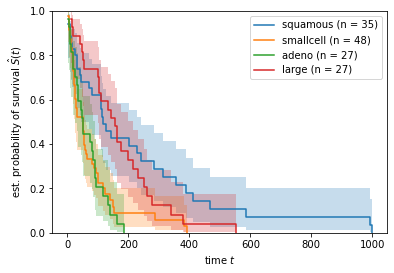
In this case, we observe a pronounced difference between two groups. Patients with squamous or large cells seem to have a better prognosis compared to patients with small or adeno cells.
Multivariate Survival Models#
In the Kaplan-Meier approach used above, we estimated multiple survival curves by dividing the dataset into smaller sub-groups according to a variable. If we want to consider more than 1 or 2 variables, this approach quickly becomes infeasible, because subgroups will get very small. Instead, we can use a linear model, Cox’s proportional hazard’s model, to estimate the impact each variable has on survival.
First however, we need to convert the categorical variables in the data set into numeric values.
[7]:
from sksurv.preprocessing import OneHotEncoder
data_x_numeric = OneHotEncoder().fit_transform(data_x)
data_x_numeric.head()
[7]:
| Age_in_years | Celltype=large | Celltype=smallcell | Celltype=squamous | Karnofsky_score | Months_from_Diagnosis | Prior_therapy=yes | Treatment=test | |
|---|---|---|---|---|---|---|---|---|
| 0 | 69.0 | 0.0 | 0.0 | 1.0 | 60.0 | 7.0 | 0.0 | 0.0 |
| 1 | 64.0 | 0.0 | 0.0 | 1.0 | 70.0 | 5.0 | 1.0 | 0.0 |
| 2 | 38.0 | 0.0 | 0.0 | 1.0 | 60.0 | 3.0 | 0.0 | 0.0 |
| 3 | 63.0 | 0.0 | 0.0 | 1.0 | 60.0 | 9.0 | 1.0 | 0.0 |
| 4 | 65.0 | 0.0 | 0.0 | 1.0 | 70.0 | 11.0 | 1.0 | 0.0 |
Survival models in scikit-survival follow the same rules as estimators in scikit-learn, i.e., they have a fit method, which expects a data matrix and a structured array of survival times and binary event indicators.
[8]:
from sklearn import set_config
from sksurv.linear_model import CoxPHSurvivalAnalysis
set_config(display="text") # displays text representation of estimators
estimator = CoxPHSurvivalAnalysis()
estimator.fit(data_x_numeric, data_y)
[8]:
CoxPHSurvivalAnalysis()
The result is a vector of coefficients, one for each variable, where each value corresponds to the log hazard ratio.
[9]:
pd.Series(estimator.coef_, index=data_x_numeric.columns)
[9]:
Age_in_years -0.008549
Celltype=large -0.788672
Celltype=smallcell -0.331813
Celltype=squamous -1.188299
Karnofsky_score -0.032622
Months_from_Diagnosis -0.000092
Prior_therapy=yes 0.072327
Treatment=test 0.289936
dtype: float64
Using the fitted model, we can predict a patient-specific survival function, by passing an appropriate data matrix to the estimator’s predict_survival_function method.
First, let’s create a set of four synthetic patients.
[10]:
x_new = pd.DataFrame.from_dict(
{
1: [65, 0, 0, 1, 60, 1, 0, 1],
2: [65, 0, 0, 1, 60, 1, 0, 0],
3: [65, 0, 1, 0, 60, 1, 0, 0],
4: [65, 0, 1, 0, 60, 1, 0, 1],
},
columns=data_x_numeric.columns,
orient="index",
)
x_new
[10]:
| Age_in_years | Celltype=large | Celltype=smallcell | Celltype=squamous | Karnofsky_score | Months_from_Diagnosis | Prior_therapy=yes | Treatment=test | |
|---|---|---|---|---|---|---|---|---|
| 1 | 65 | 0 | 0 | 1 | 60 | 1 | 0 | 1 |
| 2 | 65 | 0 | 0 | 1 | 60 | 1 | 0 | 0 |
| 3 | 65 | 0 | 1 | 0 | 60 | 1 | 0 | 0 |
| 4 | 65 | 0 | 1 | 0 | 60 | 1 | 0 | 1 |
Similar to kaplan_meier_estimator, the predict_survival_function method returns a sequence of step functions, which we can plot.
[11]:
import numpy as np
pred_surv = estimator.predict_survival_function(x_new)
time_points = np.arange(1, 1000)
for i, surv_func in enumerate(pred_surv):
plt.step(time_points, surv_func(time_points), where="post", label=f"Sample {i + 1}")
plt.ylabel(r"est. probability of survival $\hat{S}(t)$")
plt.xlabel("time $t$")
plt.legend(loc="best")
[11]:
<matplotlib.legend.Legend at 0x121a78b90>
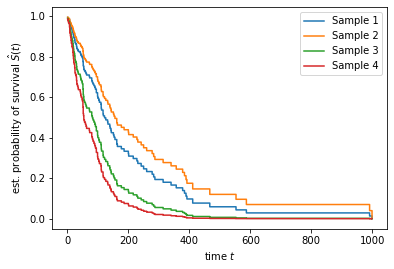
Measuring the Performance of Survival Models#
Once we fit a survival model, we usually want to assess how well a model can actually predict survival. Our test data is usually subject to censoring too, therefore metrics like root mean squared error or correlation are unsuitable. Instead, we use generalization of the area under the receiver operating characteristic (ROC) curve called Harrell’s concordance index or c-index.
The interpretation is identical to the traditional area under the ROC curve metric for binary classification:
a value of 0.5 denotes a random model,
a value of 1.0 denotes a perfect model,
a value of 0.0 denotes a perfectly wrong model.
[12]:
from sksurv.metrics import concordance_index_censored
prediction = estimator.predict(data_x_numeric)
result = concordance_index_censored(data_y["Status"], data_y["Survival_in_days"], prediction)
f"{result[0]:.5f}"
[12]:
'0.73626'
or alternatively
[13]:
c_index = estimator.score(data_x_numeric, data_y)
f"{c_index:.5f}"
[13]:
'0.73626'
Our model’s c-index indicates that the model clearly performs better than random, but is also far from perfect.
Feature Selection: Which Variable is Most Predictive?#
The model above considered all available variables for prediction. Next, we want to investigate which single variable is the best risk predictor. Therefore, we fit a Cox model to each variable individually and record the c-index on the training set.
[14]:
import numpy as np
def fit_and_score_features(X, y):
n_features = X.shape[1]
scores = np.empty(n_features)
m = CoxPHSurvivalAnalysis()
for j in range(n_features):
Xj = X[:, j : j + 1]
m.fit(Xj, y)
scores[j] = m.score(Xj, y)
return scores
scores = fit_and_score_features(data_x_numeric.values, data_y)
pd.Series(scores, index=data_x_numeric.columns).sort_values(ascending=False)
[14]:
Karnofsky_score 0.709280
Celltype=smallcell 0.572581
Celltype=large 0.561620
Celltype=squamous 0.550545
Treatment=test 0.525386
Age_in_years 0.515107
Months_from_Diagnosis 0.509030
Prior_therapy=yes 0.494434
dtype: float64
Karnofsky_score is the best variable, whereas Months_from_Diagnosis and Prior_therapy='yes' have almost no predictive power on their own.
Next, we want to build a parsimonious model by excluding irrelevant features. We could use the ranking from above, but would need to determine what the optimal cut-off should be. Luckily, scikit-learn has built-in support for performing grid search.
First, we create a pipeline that puts all the parts together.
[15]:
from sklearn.feature_selection import SelectKBest
from sklearn.pipeline import Pipeline
pipe = Pipeline(
[
("encode", OneHotEncoder()),
("select", SelectKBest(fit_and_score_features, k=3)),
("model", CoxPHSurvivalAnalysis()),
]
)
Next, we need to define the range of parameters we want to explore during grid search. Here, we want to optimize the parameter k of the SelectKBest class and allow k to vary from 1 feature to all 8 features.
[16]:
from sklearn.model_selection import GridSearchCV, KFold
param_grid = {"select__k": np.arange(1, data_x_numeric.shape[1] + 1)}
cv = KFold(n_splits=3, random_state=1, shuffle=True)
gcv = GridSearchCV(pipe, param_grid, return_train_score=True, cv=cv)
gcv.fit(data_x, data_y)
results = pd.DataFrame(gcv.cv_results_).sort_values(by="mean_test_score", ascending=False)
results.loc[:, ~results.columns.str.endswith("_time")]
[16]:
| param_select__k | params | split0_test_score | split1_test_score | split2_test_score | mean_test_score | std_test_score | rank_test_score | split0_train_score | split1_train_score | split2_train_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | {'select__k': 5} | 0.716093 | 0.719862 | 0.716685 | 0.717547 | 0.001655 | 1 | 0.732087 | 0.742432 | 0.731710 | 0.735410 | 0.004968 |
| 3 | 4 | {'select__k': 4} | 0.697368 | 0.722332 | 0.727324 | 0.715675 | 0.013104 | 2 | 0.732477 | 0.743090 | 0.727138 | 0.734235 | 0.006630 |
| 7 | 8 | {'select__k': 8} | 0.706478 | 0.723320 | 0.716685 | 0.715494 | 0.006927 | 3 | 0.739356 | 0.746249 | 0.737519 | 0.741041 | 0.003758 |
| 5 | 6 | {'select__k': 6} | 0.704453 | 0.719368 | 0.716685 | 0.713502 | 0.006491 | 4 | 0.735722 | 0.747565 | 0.731710 | 0.738332 | 0.006731 |
| 6 | 7 | {'select__k': 7} | 0.700405 | 0.719368 | 0.720045 | 0.713272 | 0.009103 | 5 | 0.741173 | 0.742564 | 0.728621 | 0.737453 | 0.006271 |
| 1 | 2 | {'select__k': 2} | 0.699393 | 0.717885 | 0.718365 | 0.711881 | 0.008833 | 6 | 0.732087 | 0.727428 | 0.714409 | 0.724642 | 0.007481 |
| 0 | 1 | {'select__k': 1} | 0.698887 | 0.707510 | 0.712206 | 0.706201 | 0.005516 | 7 | 0.710670 | 0.714793 | 0.700445 | 0.708636 | 0.006032 |
| 2 | 3 | {'select__k': 3} | 0.708502 | 0.714427 | 0.694849 | 0.705926 | 0.008198 | 8 | 0.734034 | 0.722559 | 0.716634 | 0.724409 | 0.007223 |
The results show that it is sufficient to select the 5 most predictive features.
[17]:
pipe.set_params(**gcv.best_params_)
pipe.fit(data_x, data_y)
encoder, transformer, final_estimator = (s[1] for s in pipe.steps)
pd.Series(final_estimator.coef_, index=encoder.encoded_columns_[transformer.get_support()])
[17]:
Celltype=large -0.754714
Celltype=smallcell -0.328059
Celltype=squamous -1.147673
Karnofsky_score -0.031112
Treatment=test 0.257313
dtype: float64
What’s next?#
Cox’s proportional hazards model is by far the most popular survival model, because once trained, it is easy to interpret. However, if prediction performance is the main objective, more sophisticated, non-linear or ensemble models might lead to better results. Before you dive deeper into the various survival models, it is highly recommended reading this notebook for getting a better understanding on how to evaluate survival models. The User Guide is a good starting point to learn more about various models implemented in scikit-survival, and the API reference contains a full list of available classes and functions and their parameters. In addition, you can use any unsupervised pre-processing method available with scikit-learn, for instance, you could perform dimensionality reduction using Non-Negative Matrix Factorization (NMF), before training a Cox model.