Introduction to Survival Support Vector Machine#
This guide demonstrates how to use the efficient implementation of Survival Support Vector Machines, which is an extension of the standard Support Vector Machine to right-censored time-to-event data. Its main advantage is that it can account for complex, non-linear relationships between features and survival via the so-called kernel trick. A kernel function implicitly maps the input features into high-dimensional feature spaces where survival can be described by a hyperplane. This makes Survival Support Vector Machines extremely versatile and applicable to a wide a range of data. A popular example for such a kernel function is the Radial Basis Function.
Survival analysis in the context of Support Vector Machines can be described in two different ways:
As a ranking problem: the model learns to assign samples with shorter survival times a lower rank by considering all possible pairs of samples in the training data.
As a regression problem: the model learns to directly predict the (log) survival time.
In both cases, the disadvantage is that predictions cannot be easily related to standard quantities in survival analysis, namely survival function and cumulative hazard function. Moreover, they have to retain a copy of the training data to do predictions.
Let’s start by taking a closer look at the Linear Survival Support Vector Machine, which does not allow selecting a specific kernel function, but can be fitted faster than the more generic Kernel Survival Support Vector Machine.
Linear Survival Support Vector Machine#
The class sksurv.svm.FastSurvivalSVM is used to train a linear Survival Support Vector Machine. Training data consists of \(n\) triplets \((\mathbf{x}_i, y_i, \delta_i)\), where \(\mathbf{x}_i\) is a \(d\)-dimensional feature vector, \(y_i > 0\) the survival time or time of censoring, and \(\delta_i \in \{0,1\}\) the binary event indicator. Using the training data, the objective is to minimize the following function:
\begin{equation} \arg \min_{\mathbf{w}, b} \frac{1}{2} \mathbf{w}^T \mathbf{w}+ \frac{\alpha}{2} \left[ r \sum_{i,j \in \mathcal{P}} \max(0, 1 - (\mathbf{w}^T \mathbf{x}_i - \mathbf{w}^T \mathbf{x}_j))^2 + (1 - r) \sum_{i=0}^n \left( \zeta_{\mathbf{w},b} (y_i, x_i, \delta_i) \right)^2 \right] \end{equation}
\begin{equation} \zeta_{\mathbf{w},b} (y_i, \mathbf{x}_i, \delta_i) = \begin{cases} \max(0, y_i - \mathbf{w}^T \mathbf{x}_i - b) & \text{if $\delta_i = 0$,}\\ y_i - \mathbf{w}^T \mathbf{x}_i - b & \text{if $\delta_i = 1$,}\\ \end{cases} \end{equation}
\begin{equation} \mathcal{P} = \{ (i, j)~|~y_i > y_j \land \delta_j = 1 \}_{i,j=1,\dots,n} \end{equation}
The hyper-parameter \(\alpha > 0\) determines the amount of regularization to apply: a smaller value increases the amount of regularization and a higher value reduces the amount of regularization. The hyper-parameter \(r \in [0; 1]\) determines the trade-off between the ranking objective and the regression objective. If \(r = 1\) it reduces to the ranking objective, and if \(r = 0\) to the regression objective.
The class sksurv.svm.FastSurvivalSVM adheres to interfaces used in scikit-learn and thus it is possible to combine it with auxiliary classes and functions from scikit-learn. In this example, we are going to use the ranking objective (\(r = 1\)) and GridSearchCV to determine the best setting for the hyper-parameter \(\alpha\) on the Veteran’s Lung Cancer data.
First, we have to import the classes we are going to use.
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas
import seaborn as sns
from sklearn import set_config
from sklearn.model_selection import GridSearchCV, ShuffleSplit
from sksurv.column import encode_categorical
from sksurv.datasets import load_veterans_lung_cancer
from sksurv.metrics import concordance_index_censored
from sksurv.svm import FastSurvivalSVM
set_config(display="text") # displays text representation of estimators
sns.set_style("whitegrid")
Next, we load data of the Veteran’s Administration Lung Cancer Trial from disk and convert it to numeric values. The data consists of 137 patients and 6 features. The primary outcome measure is death (Status, Survival_in_days). The original data can be retrieved from http://lib.stat.cmu.edu/datasets/veteran.
[2]:
data_x, y = load_veterans_lung_cancer()
x = encode_categorical(data_x)
data_x is a data frame containing the features, and y is a structured array containing the event indicator \(\delta_i\), as boolean, and the survival/censoring time \(y_i\) for training.
Now, we are essentially ready to start training, but before let’s determine what the amount of censoring for this data is and plot the survival/censoring times.
[3]:
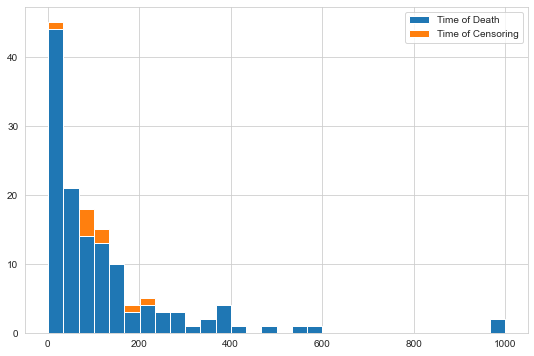
n_censored = y.shape[0] - y["Status"].sum()
print(f"{n_censored / y.shape[0] * 100:.1f}% of records are censored")
6.6% of records are censored
[4]:
plt.figure(figsize=(9, 6))
val, bins, patches = plt.hist(
(y["Survival_in_days"][y["Status"]], y["Survival_in_days"][~y["Status"]]), bins=30, stacked=True
)
_ = plt.legend(patches, ["Time of Death", "Time of Censoring"])
First, we need to create an initial model with default parameters that is subsequently used in the grid search.
[5]:
estimator = FastSurvivalSVM(max_iter=1000, tol=1e-5, random_state=0)
Next, we define a function for evaluating the performance of models during grid search. We use Harrell’s concordance index.
[6]:
def score_survival_model(model, X, y):
prediction = model.predict(X)
result = concordance_index_censored(y["Status"], y["Survival_in_days"], prediction)
return result[0]
The last part of the setup specifies the set of parameters we want to try and how many repetitions of training and testing we want to perform for each parameter setting. In the end, the parameters that on average performed best across all test sets (100 in this case) are selected. GridSearchCV can leverage multiple cores by evaluating multiple parameter settings concurrently (4 jobs in this example).
[7]:
param_grid = {"alpha": [2.0**v for v in range(-12, 13, 2)]}
cv = ShuffleSplit(n_splits=100, test_size=0.5, random_state=0)
gcv = GridSearchCV(estimator, param_grid, scoring=score_survival_model, n_jobs=1, refit=False, cv=cv)
Finally, start the hyper-parameter search. This can take a while since a total of 13 * 100 = 1300 fits have to be evaluated.
[8]:
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
gcv = gcv.fit(x, y)
Let’s check what is the best average performance across 100 random train/test splits we got and the corresponding hyper-parameters.
[9]:
f"{gcv.best_score_:.3f}", gcv.best_params_
[9]:
('0.720', {'alpha': 0.00390625})
Finally, we retrieve all 100 test scores for each parameter setting and visualize their distribution by box plots.
[10]:
def plot_performance(gcv):
n_splits = gcv.cv.n_splits
cv_scores = {"alpha": [], "test_score": [], "split": []}
order = []
for i, params in enumerate(gcv.cv_results_["params"]):
name = f'{params["alpha"]:.5f}'
order.append(name)
for j in range(n_splits):
vs = gcv.cv_results_[f"split{j}_test_score"][i]
cv_scores["alpha"].append(name)
cv_scores["test_score"].append(vs)
cv_scores["split"].append(j)
df = pandas.DataFrame.from_dict(cv_scores)
_, ax = plt.subplots(figsize=(11, 6))
sns.boxplot(x="alpha", y="test_score", hue="alpha", data=df, order=order, ax=ax)
_, xtext = plt.xticks()
for t in xtext:
t.set_rotation("vertical")
[11]:
plot_performance(gcv)
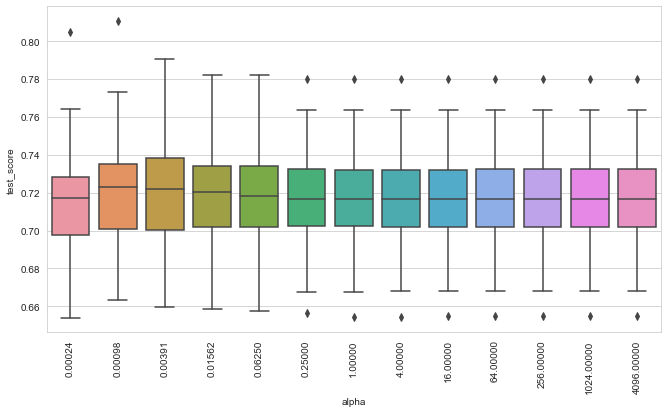
We can observe that the model seems to be relative robust with respect to the choice for \(\alpha\) for this dataset. Let’s fit a model using the \(\alpha\) value that performed best.
[12]:
estimator.set_params(**gcv.best_params_)
estimator.fit(x, y)
[12]:
FastSurvivalSVM(alpha=0.00390625, max_iter=1000, optimizer='avltree',
random_state=0, tol=1e-05)
It is important to remember that only if the ranking objective is used exclusively (\(r = 1\)), that predictions denote risk scores, i.e. a higher predicted value indicates shorter survival, a lower value longer survival.
[13]:
pred = estimator.predict(x.iloc[:2])
print(np.round(pred, 3))
print(y[:2])
[-1.59 -1.687]
[( True, 72.) ( True, 411.)]
The model predicted that the first sample has a lower risk than the second sample, which is in concordance with the actual survival times.
Regression Objective#
If the regression objective is used (\(r < 1\)), the semantics are different, because now predictions are on the time scale and lower predicted values indicate shorter survival, higher values longer survival. Moreover, we saw from the histogram of observed times above that the distribution is skewed, therefore the survival/censoring times will be log-transformed by the FastSurvivalSVM internally, when using a \(r < 1\).
Let’s fit a model using the regression objective (\(r = 0\)) and compare its performance to the ranking model from above.
[14]:
ref_estimator = FastSurvivalSVM(rank_ratio=0.0, max_iter=1000, tol=1e-5, random_state=0)
ref_estimator.fit(x, y)
cindex = concordance_index_censored(
y["Status"],
y["Survival_in_days"],
-ref_estimator.predict(x), # flip sign to obtain risk scores
)
f"{cindex[0]:.3f}"
[14]:
'0.736'
Note that concordance_index_censored expects risk scores, therefore, we had to flip the sign of predictions. The resulting performance of the regression model is comparable to the of the ranking model above.
[15]:
pred = ref_estimator.predict(x.iloc[:2])
print(np.round(pred, 3))
[120.786 149.963]
Kernel Survival Support Vector Machine#
The Kernel Survival Support Vector Machine is a generalization of the Linear Survival Support Vector Machine that can account for more complex relationships between features and survival time, it is implemented in sksurv.svm.FastKernelSurvivalSVM. The disadvantage is that the choice of kernel function and its hyper-parameters is often not straightforward and requires tuning to obtain good results. For instance, the Radial Basis
Function has a hyper-parameter \(\gamma\) that needs to be set: \(k(x, x^\prime) = \exp(-\gamma \|x-x^\prime \|^2)\). There are many other built-in kernel functions that can be used by passing their name as kernel parameter to FastKernelSurvivalSVM.
In this example, we are going to use the clinical kernel, because it is able to distinguish between continuous, ordinal, and nominal attributes. As this is a custom kernel function, we first need to pre-compute the kernel matrix.
[16]:
from sksurv.kernels import clinical_kernel
from sksurv.svm import FastKernelSurvivalSVM
[17]:
kernel_matrix = clinical_kernel(data_x)
As with the Linear Survival Support Vector Machine above, we are going to determine the optimal \(\alpha\) value by using GridSearchCV.
[18]:
kssvm = FastKernelSurvivalSVM(optimizer="rbtree", kernel="precomputed", random_state=0)
kgcv = GridSearchCV(kssvm, param_grid, scoring=score_survival_model, n_jobs=1, refit=False, cv=cv)
Note that when using a custom kernel, we do not pass the original data (data_x) to the fit function, but the pre-computed, square kernel matrix.
[19]:
kgcv = kgcv.fit(kernel_matrix, y)
Now, print the best average concordance index and the corresponding parameters.
[20]:
f"{kgcv.best_score_:.3f}", kgcv.best_params_
[20]:
('0.709', {'alpha': 0.015625})
Finally, we visualize the distribution of test scores obtained via cross-validation.
[21]:
plot_performance(kgcv)
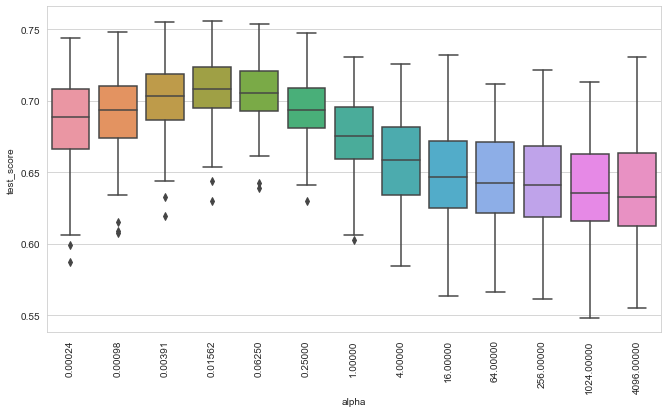
We can see that the choice of \(\alpha\) is much more important here, compared to the Linear Survival Support Vector Machine. Nevertheless, the best performance is below that of the linear model, which illustrates that choosing a good kernel function is essential, but also a non-trivial task.
References#
Pölsterl, S., Navab, N., and Katouzian, A., Fast Training of Support Vector Machines for Survival Analysis, Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2015, Porto, Portugal, Lecture Notes in Computer Science, vol. 9285, pp. 243-259 (2015)
Pölsterl, S., Navab, N., and Katouzian, A., An Efficient Training Algorithm for Kernel Survival Support Vector Machines 4th Workshop on Machine Learning in Life Sciences, 23 September 2016, Riva del Garda, Italy